Accessing SPARQL Endpoints from within Yahoo Pipes
Well, at least until the 'Semantic Web Pipes' are ready for prime time: a webservice that allows to query sparql endpoints from within Yahoo Pipes. Look at the example below: It shows a simple pipe that takes a name as input, uses it to query the dblp sparql endpoint and returns the result as web page, JSON and RSS. You can try the pipe here. Surely getting an RSS feed for the publications from dblp could have been achieved without RDF-SPARQL-Pipes, however, we can now access all kinds of SPARQL endpoints and have the entire functionality of Yahoo Pipes at hand to combine it with other (possibly non-SemWeb) content.
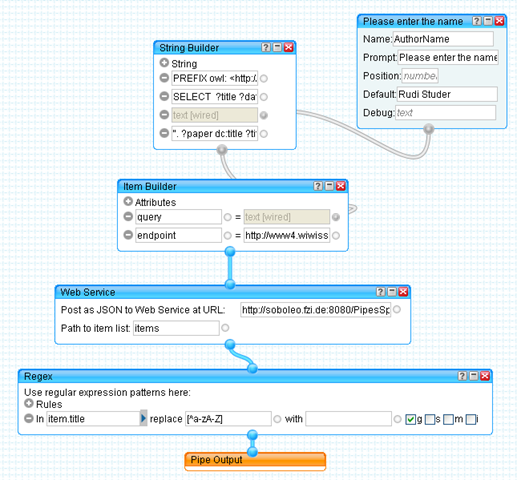
Let me quickly explain the pipe: The 'Please enter the name' element defines the 'name' input to the pipe. The 'String Builder' block uses this name to build a sparql query and the 'Item Builder' combines the query and the endpoint URL (http://www4.wiwiss.fu-berlin.de/dblp/sparql, in this case) into an item that will be send to the web service. The web service (that lives at http://soboleo.fzi.de:8080/PipesSparqlr/sparql [1]) takes the query and endpoint URL, sends the query to the endpoint and translates the answer to a simpler JSON format[2]. Any error encountered is simple returned instead of a result - so you are able to see it in the debugger view of Yahoo Pipes. The last operator, the Regex element, removes anything but characters from the item's title - sadly that's necessary because somewhere along the line the character encodings get mixed up and this is tripping up Yahoo Pipes so badly, that no result is returned as soon as one of the titles contains something like for example a German 'ä' or 'ö'. I'll try to fix this someday. The source code for the webservice (all ~100 lines of it ;) ) is available here - feel free to use it anyway you like. You'll need the JSON library and Java 1.5+ to compile, and some servlet container (I use tomcat 5.5.something) to run it.
[1]: Feel free to use this webservice but don't count on it staying there forever.
[2]: Just passing through the SPARQL query result XML caused problems with Yahoo Pipes which expects either JSON or RSS.
Labels: Mashup, SemanticWeb, Web





